Gather document samples for machine learning phase. For best results, a minimum of 1000 images are required, with varying qualities, sizes, and orientations.
Step 2
Use machine learning and computer vision tools to learn documents formats. Generate data sets per document and indexing type.
Step 3
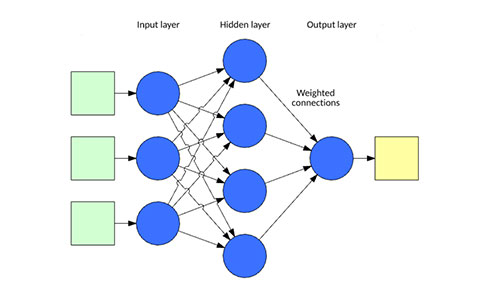
Build Neural Network based on machine learnt models for document classification and reading automation.
Step 4
Generate container with all models in Neural Network (DFVision)! Service ready for integration with Captiva or any document capture system.